Bayesian Learning: Clustering with the Dirichlet Process Mixture Model
Final dissertation for the BSc in Economics, Management and Computer Science at Bocconi University.
Supervisor: Prof. Antonio Lijoi
Abstract
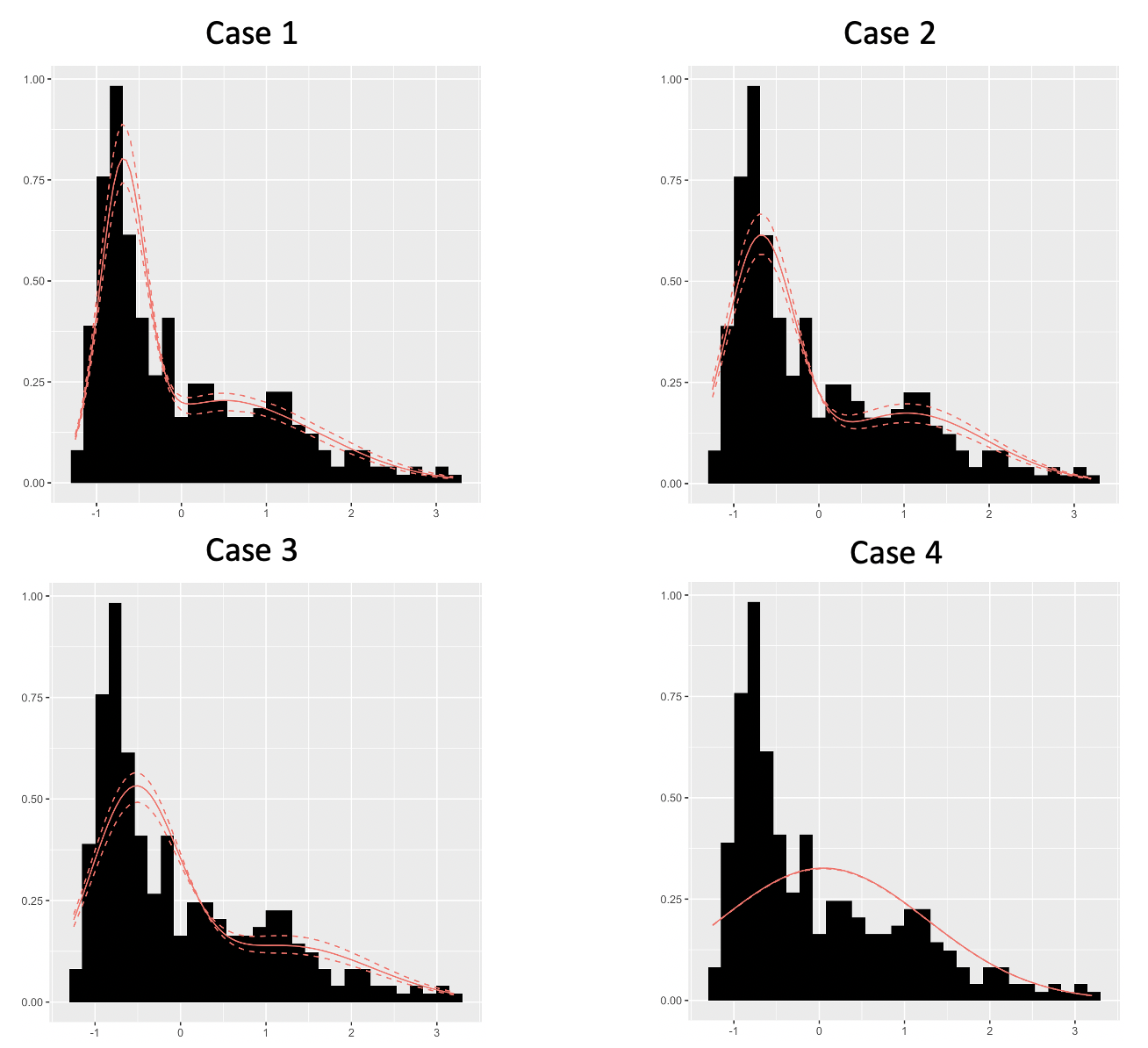
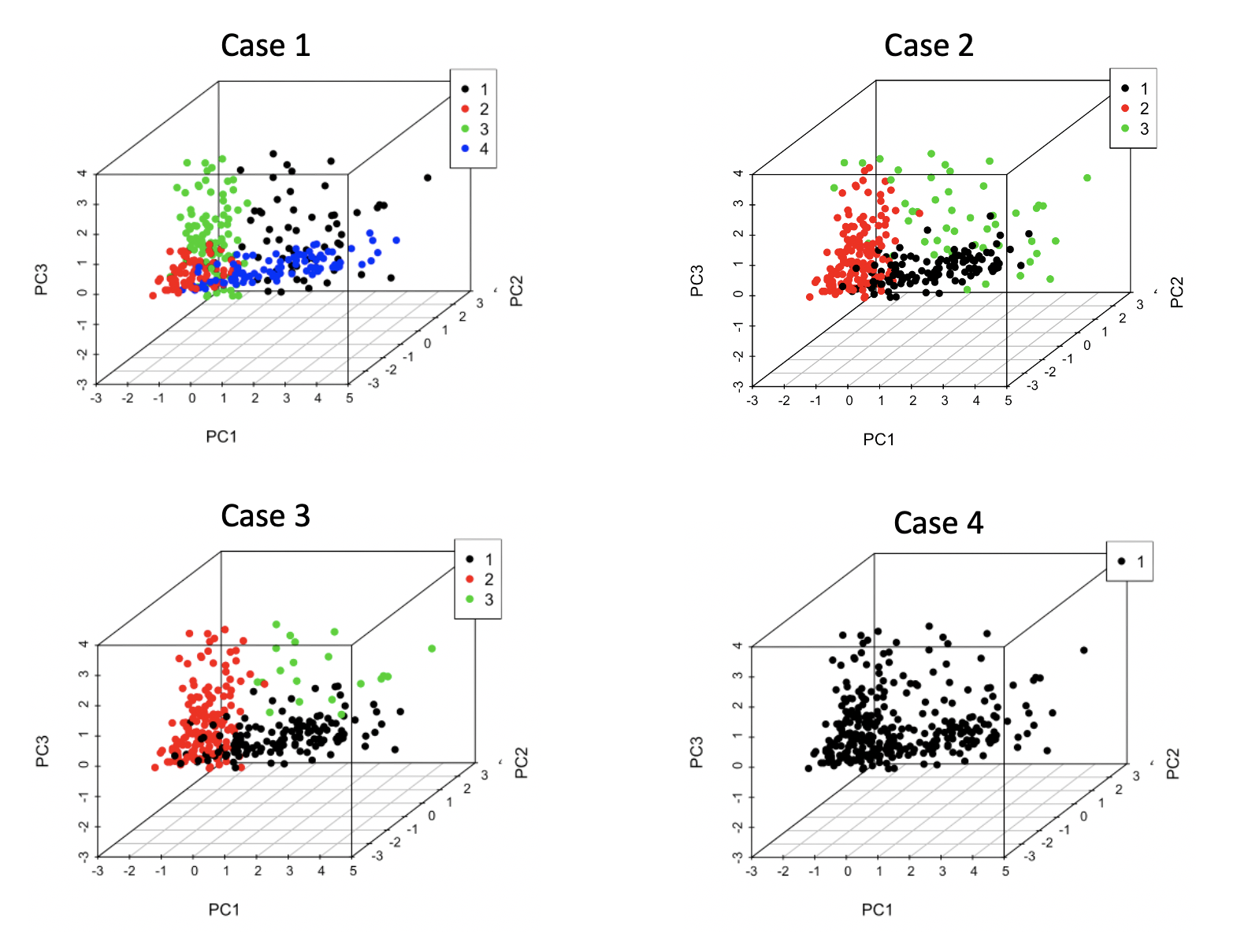
Bayesian nonparametric models have gained widespread popularity for many machine learning problems thanks to their higher modeling flexibility with respect to parametric models. This paper explores the application of Bayesian nonparametrics to clustering, by means of the Dirichlet process mixture model (DPMM). It has been structured as a discussion of all the fundamental theory behind the DPMM applied to cluster analysis, including the background knowledge necessary for its full understanding. Thus, the paper begins by introducing the general Bayesian nonparametric framework, including its theoretical foundation represented by de Finetti’s representation theorem. Moreover, it provides a detailed review of finite mixture modeling, in order to understand its limitations due to the finite number of clusters assumed in the population. Then, it continues with an explanation of the Dirichlet process, focusing on its constructive definition and the Pólya urn scheme, and of Markov chain Monte Carlo methods. The main results concerning the DPMM are then analyzed, with particular attention to its clustering property, namely the distribution on partitions of experimental units that it implicitly defines, obtaining the definition of infinite mixture modeling. The theory is concluded with the description of a procedure for performing posterior inference about the cluster parameters in the DPMM, based on Gibbs sampling. The final part is about an application of the model for clustering real data, including an analysis of the sensitivity to the model hyperparameters, in order to practically show its benefits, but also put in evidence potential limitations regarding the prior parameter specification that might arise in practice.